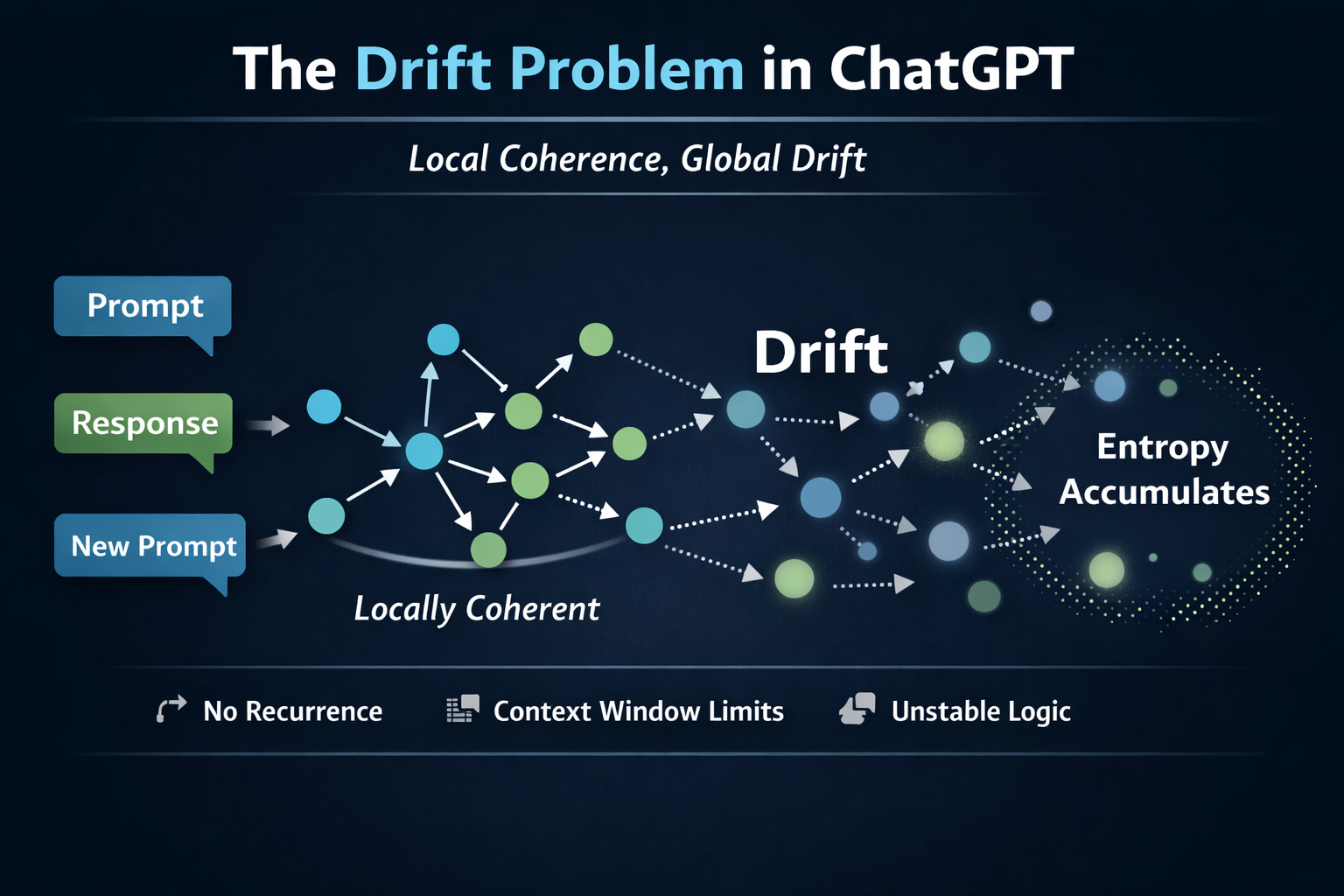
ChatGPT drift isn’t a flaw in intelligence — it’s a consequence of how attention spreads across context. In extended sessions, ChatGPT drift becomes visible as reasoning slowly loses its structural focus. Here’s how structured attention can stabilize reasoning without retraining the model.
If you’ve used ChatGPT seriously inside your organization, you’ve seen it.
It starts strong.
At first, it sounds coherent.
It even feels insightful.
And then — somewhere along the way — it drifts.

The reasoning gets fuzzy.
Meanwhile, the thread weakens.
As a result, output accelerates but coherence declines.
You didn’t change the model.
Nor did the system itself change.
So what happened?
The ChatGPT Drift Problem
Large language models are built on probabilistic attention mechanisms (the way the model decides what to focus on). At each step, the model allocates attention across tokens in context and predicts what comes next. The transformer architecture that enables this behavior was first described in the seminal paper Attention Is All You Need (Vaswani et al., 2017).
This works beautifully for:
- Language generation
- Pattern synthesis
- Drafting and ideation
But enterprise reasoning is not just pattern continuation.
It requires:
- Persistent constraints
- Hypothesis testing
- Measure alignment
- Traceable logic
Standard ChatGPT sessions do not enforce those constraints. They generate locally coherent text — but they do not guarantee global reasoning continuity.
That’s where ChatGPT drift begins. Over time, the divergence compounds.
It happens not because the model is broken — but because nothing is structuring the space of possible responses.
You Don’t Need to Retrain the Model
When people experience drift, the instinct is often:
- “We need fine-tuning.”
- “We need a custom model.”
- “We need better training data.”
However, the issue usually isn’t weight updates.
Instead, it’s attention architecture.
Not inside the transformer.
Around it.
Two Kinds of Attention
There are two different meanings of “structured attention”:
1. Architectural Attention (Inside the Model)
Transformer attention weights tokens based on learned statistical relationships. Some research extends this with explicit structural constraints (trees, sequences, CRFs).
That’s deep in the neural architecture.
FlowFrame does not modify that.
2. Operational Attention (Outside the Model)
This is where the real leverage lives.
Operational attention shapes:
- What the model is asked to attend to
- What constraints are repeated
- What anchors recur
- What artifacts persist
This is not weight training.
In practice, this is about designing constraints that stay visible.
And that is what stabilizes reasoning.
The Real Cause of Drift
ChatGPT drift occurs because:
- Context windows are finite.
- Prompts are often open-ended.
- Constraints are rarely revisited.
- Prior reasoning is not structurally reinforced.
Each response is statistically coherent — but coherence is not the same as disciplined progress.
In practice, enterprise reasoning requires recurrence.
Without it, entropy accumulates.
Stabilizing Reasoning Through Recurrence
FlowFrame approaches this differently.

Instead of letting conversation wander, it introduces a metabolization loop built around four anchors:
- Problem
- Hypothesis of Improvement
- Success Measures
- Work Product
These anchors do something subtle but powerful:
They create stable reference points.
Every iteration returns to them.
In turn, each refinement references them.
As a result, every artifact reflects them.
This does not retrain the model.
Instead, it narrows the model’s effective reasoning space.
As a result, entropy decreases and the number of active constraints increases.
It transforms acceleration into accountable progress.
From Stochastic Output to Governed Dialogue
Without structure:
- The model continues patterns.
- Insights feel plausible.
- Reasoning is hard to audit.
- Drift accumulates.
With structured recurrence:
- Hypotheses are tested against measures.
- Reasoning remains visible.
- Artifacts compound.
- Organizational memory grows.
Importantly, this is not workflow rigidity.
It is disciplined thinking.
In practice, it becomes structured attention at the dialogue level.
What Changes in Practice?
When you stabilize reasoning:
- AI becomes a cognitive amplifier, not a narrative generator.
- Strategy becomes iterative problem resolution.
- Sessions compound instead of resetting.
- Governance and creativity coexist.
You are no longer just generating content.
You are metabolizing problems into durable work products.
The Shift: From Training the Model to Training the Loop
Fine-tuning modifies weights.
By contrast, FlowFrame modifies recurrence.
Fine-tuning adjusts parameters, while FlowFrame adjusts how constraints stay active over time.
Fine-tuning changes the neural network.
FlowFrame, however, changes the reasoning rhythm.
And rhythm, in enterprise environments, is what creates trust continuity.
A Simple Way to Think About It
ChatGPT is excellent at continuing patterns.
FlowFrame makes it excellent at resolving problems.
That difference is not architectural.
It is structural.
Why This Matters Now
Human–AI collaboration is already here.
Today, the limiting factors are not model capability.
They are:
- Cognitive load
- Drift
- Loss of continuity
- Weak governance
Therefore, stabilizing reasoning without retraining the model is not just efficient.
It is strategic.
Because once reasoning is structured and persistent, every loop becomes cumulative.
As a result, every artifact becomes evidence.
And collaboration becomes measurable.
So, if you’ve experienced ChatGPT drift, the question is not:
“How do I get a better model?”
Instead, it may be:
“How do I structure attention so the model stays inside the problem?”
That is the real frontier.